November 6, 2023
XetHub as a Versioned Artifact Store for MLflow

Srini Kadamati

What is MLflow?
MLflow is a popular open source framework for managing the full lifecycle of machine learning.

For the user, a data scientist or ML practitioner, it’s fairly straightforward to get started.
Add some simple instrumentation to your ML experimentation code to log metrics and model runs (also called Artifacts)
Run the MLflow tracking server (either locally or on a remote computer) and specify a place (called an Artifact Store) to store metrics, models, etc
Compare model experiments using the MLflow Tracking UI (locally or remotely)
An artifact store can either be a database (like SQLite) or some type of file / blob store (like S3). Here are 2 common setups mentioned in the MLflow docs:
XetHub as a Better Artifact Store
XetHub is a blob store with Git versioning built in. XetHub combines the best properties of a blob store with the best properties of a Git version control system. Here's our quick breakdown of how we think about the relevant strengths & weaknesses of both systems and how we combine the best attributes from both.
Traditional Blob Store (like S3)
Strengths
Scale: Blob stores like S3 can store large amounts of data cheaply and efficiently without any limits on scale
Weaknesses
Primitives: Blob stores operate on the lowest level primitives like files & folders and struggle to provide human context on data, models, visualizations, etc
User interface: Blob stores usually have poor ergonomics for versioning and discourage end-users to version data.
Centralized Git System (like GitHub)
Strengths
Code Context: excel at versioning and providing context around code as well as hosting Markdown based documentation
Change Management for code: issues, commits, PR’s, and comments for code
Weaknesses
Scale: Git struggles to scale to the terabyte scale, and the ergonomics of Git LFS discourage many from using it.
Data & Model Context: GitHub, GitLab, etc offer poor visualizations and diffs into datasets and models
XetHub (our approach)
Strengths
Scale: Individual repos can scale to 10+ terabytes (experimentally can scale to 100 terabytes)
Scale: Deduplication of large datasets & models to reduce time spent waiting on upload
User Interface: Affordances for sharing rich context. Markdown-based documentation, CSV summaries and diffs, browsing model files using Netron (coming soon)
User Interface: 2 different access patterns: Git (with the git-xet extension) or pyxet (Pythonic access, showcased in this post) for making commits programmatically
Change management for code and data: Commits, pull requests, comments, time travel, and more
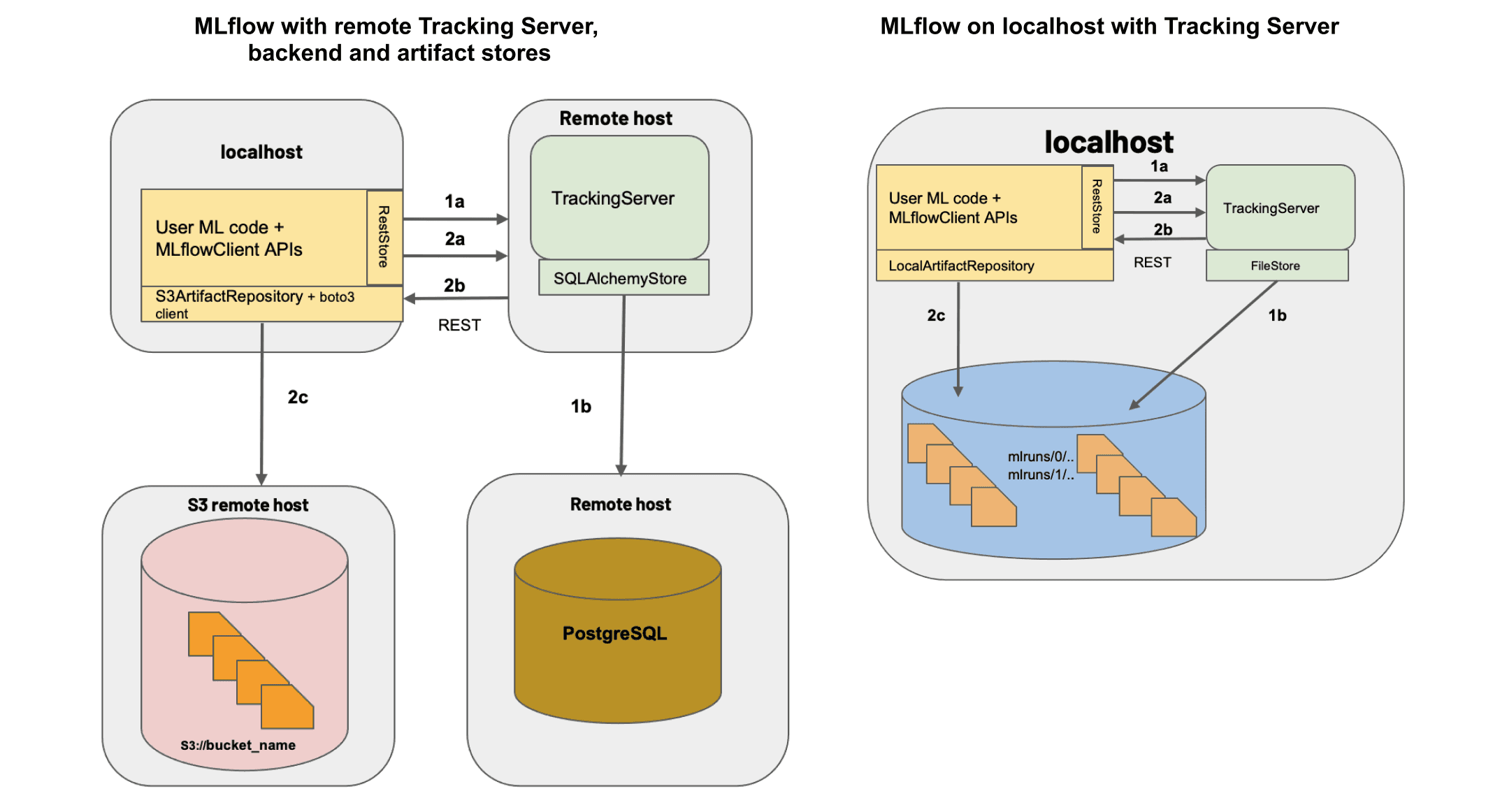
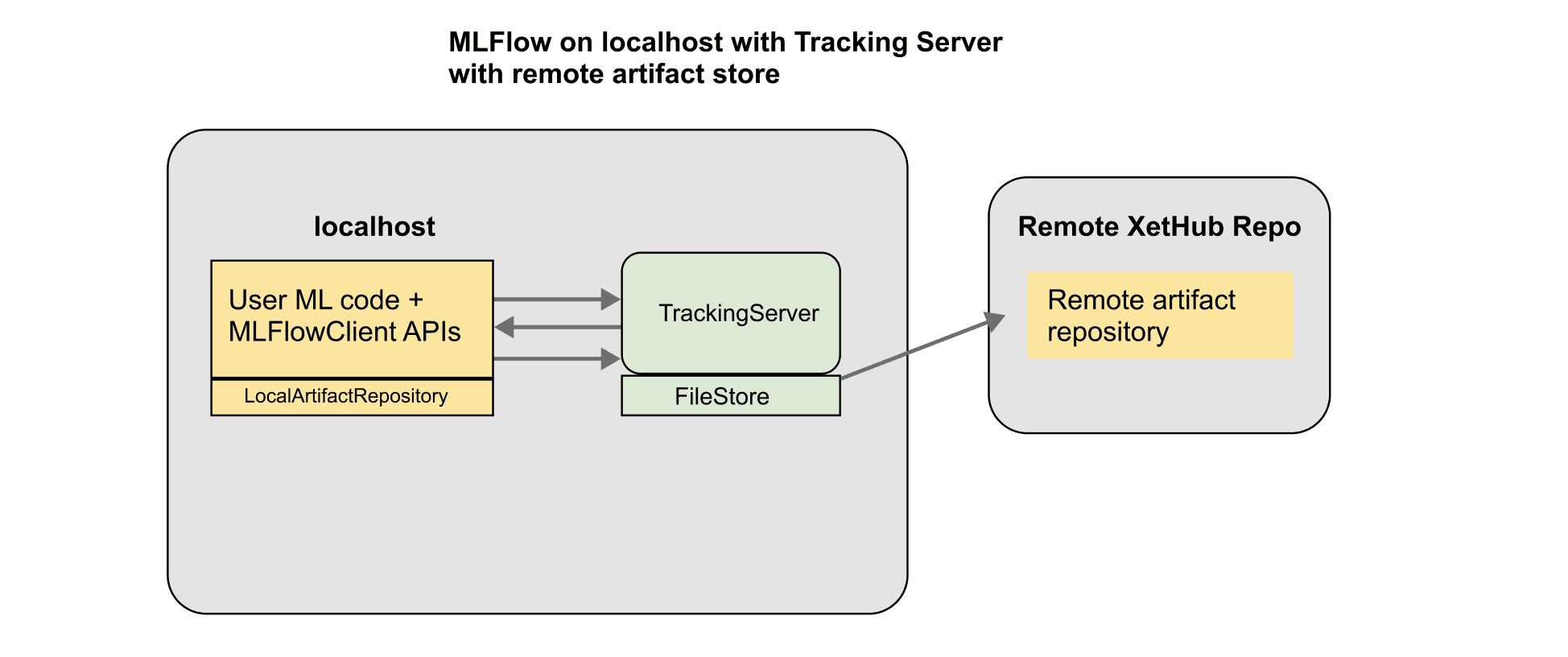
In this post, we’d like to showcase how our new MLflow integration lets you use a XetHub repo as a remote artifact store. This means that you can easily track your artifacts without having to set up any S3 buckets or databases on your own. Here’s an architecture diagram of this setup:
Quick Tutorial
Here's a quick tutorial that takes you from zero to making commits in a XetHub repo.
1. Create a free account at XetHub.com, then follow the Install Guide after signing up to install the pyxet library and authenticate with XetHub.
2. Create a new XetHub repo to log MLflow artifacts from the command line.
3. Create a new branch for tracking experiments.
4. Install the mlflow-xethub plugin using pip:
5. Then, start your MLflow server using the repo and branch you created earlier:
6. Instrument your machine learning experimentation code. Check out our GitHub README for the full code example:
7. You should see output confirming that MLflow was able to log to your remote XetHub repo:

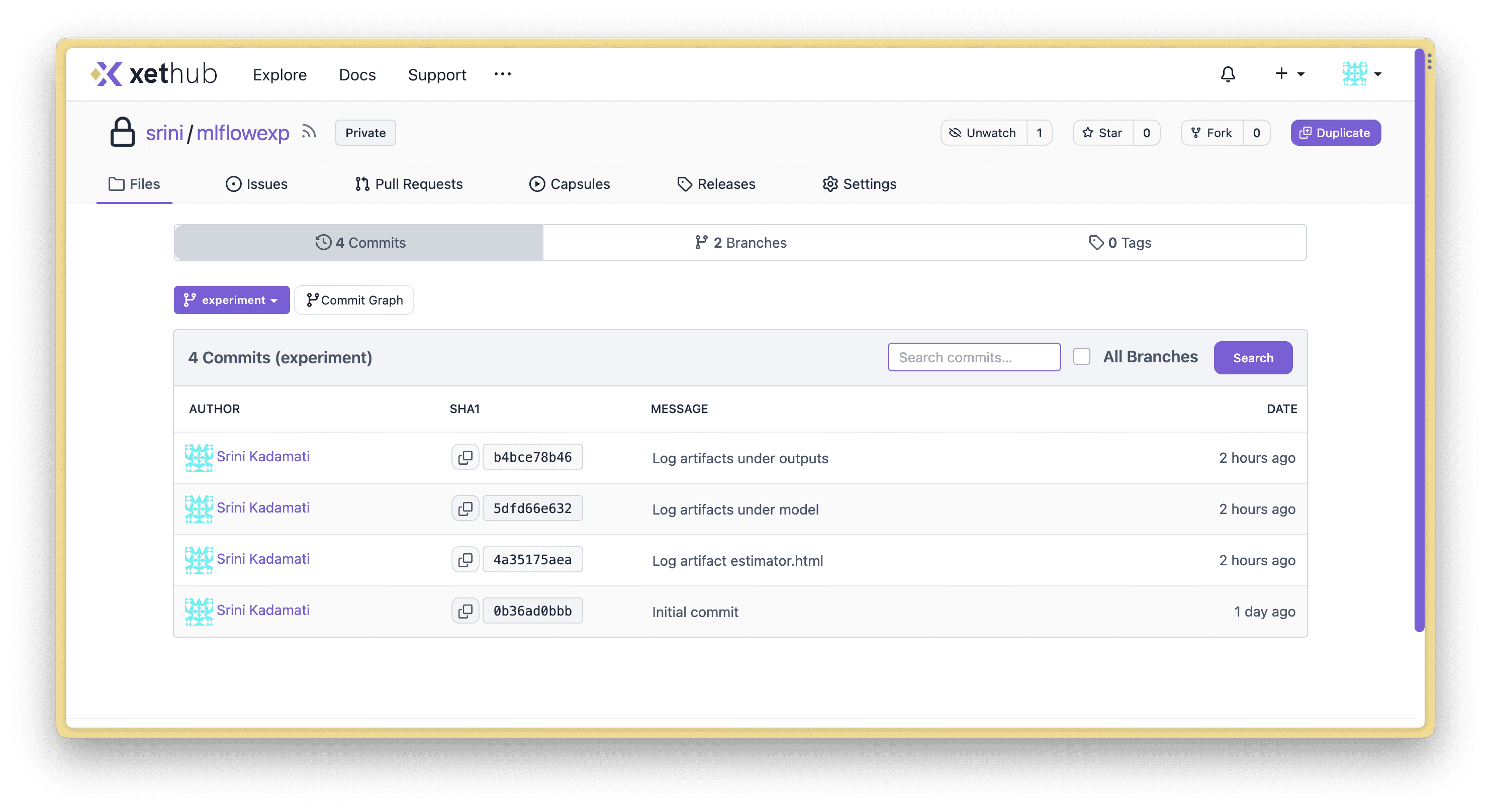
XetHub automatically versions anything that’s written to a repository. Browse to your XetHub repo to explore the files you’ve created.
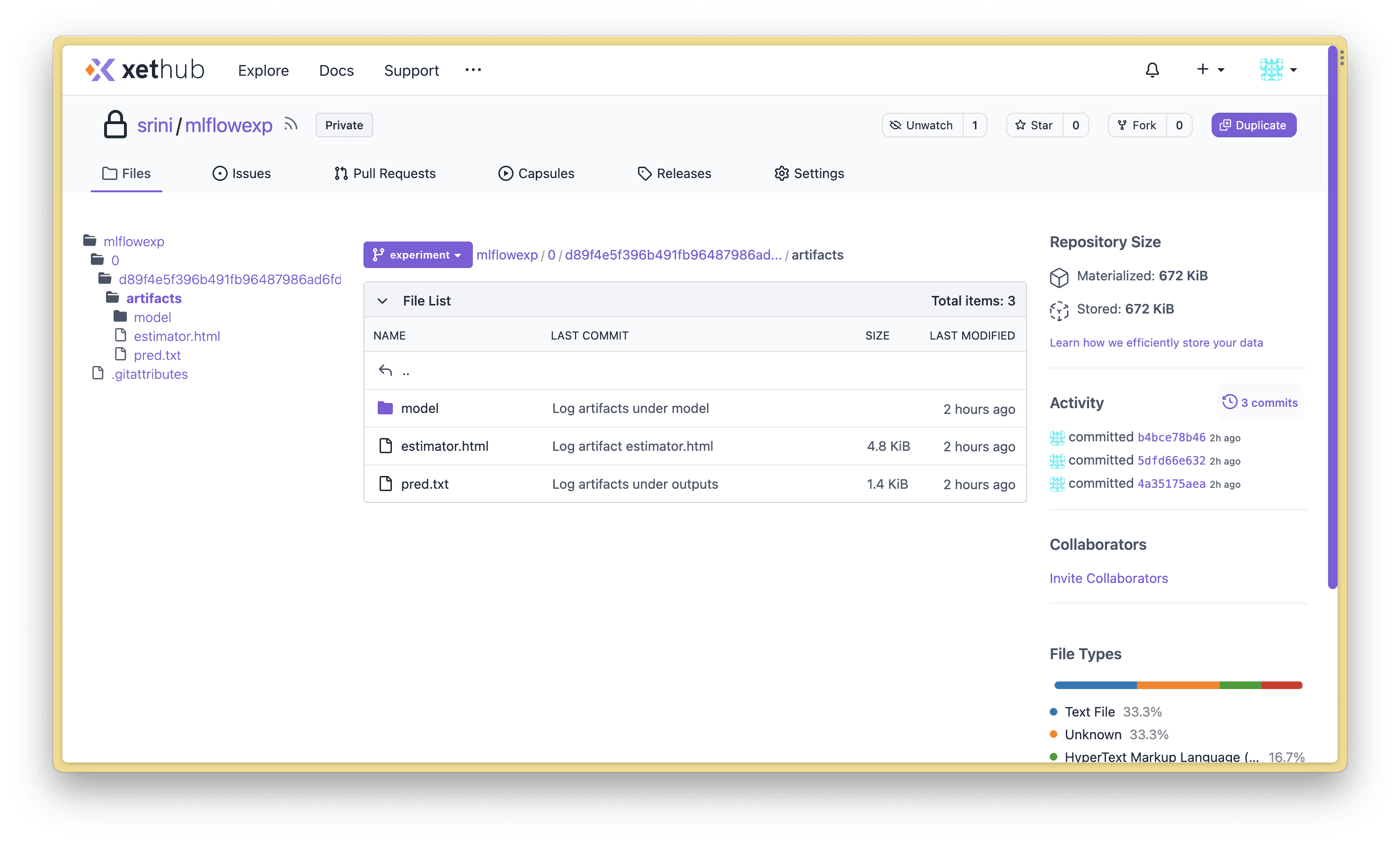
You’ll notice that each MLflow artifact was logged in a separate commit. In the next section, I’ll showcase the benefits of using commits and branches for MLflow projects:
You can find an up-to-date version of the tutorial above in our MLflow plugin docs.
Workflow Benefits of XetHub
Changes as commits
When all of your changes are commits, it lowers the friction to version since you can revert to an older version confidently.
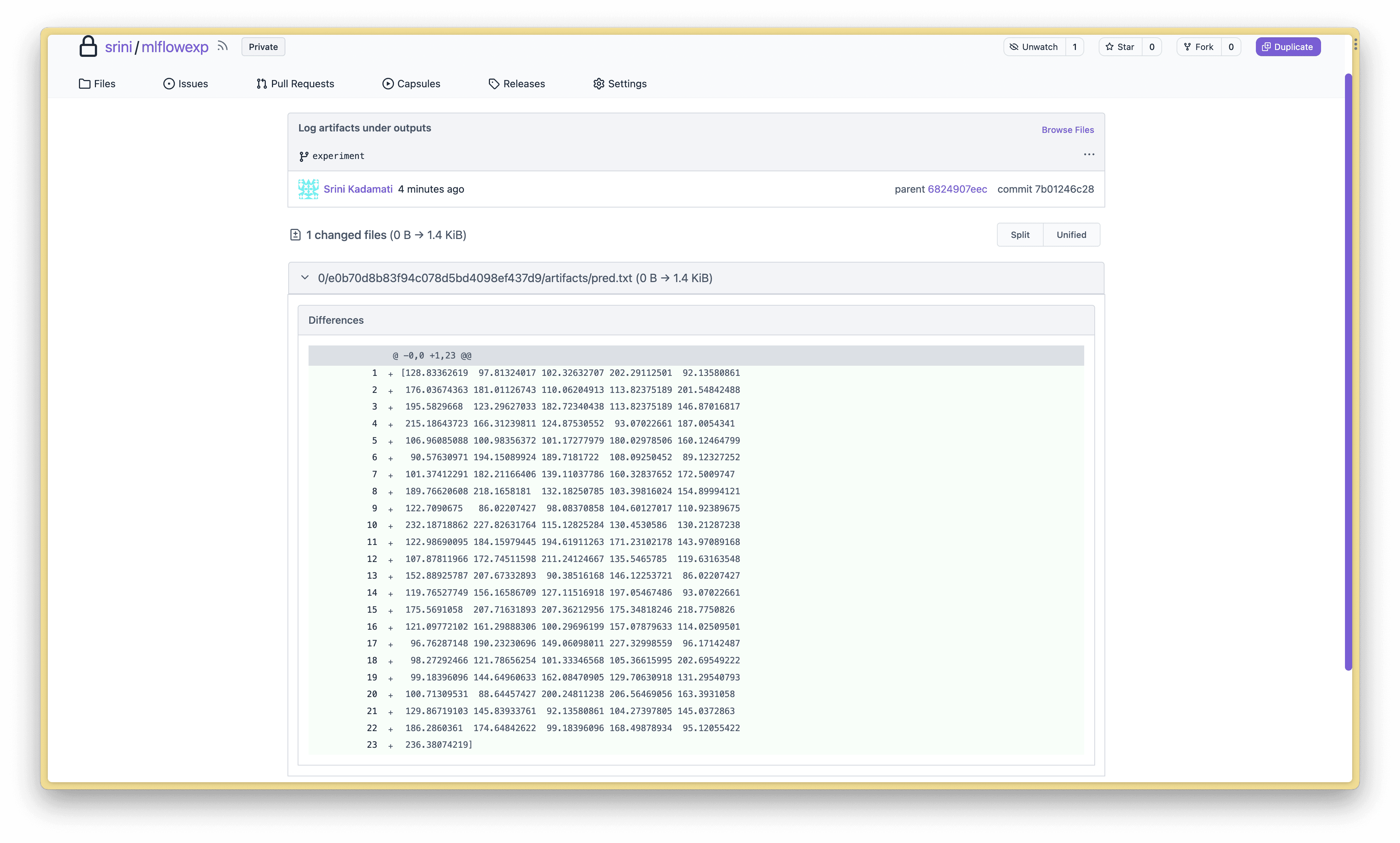
Understand what changed in each commit using the XetHub UI
At XetHub, we’re constantly adding better interfaces for browsing and understanding datasets, models, etc. Here’s what a diff looks like in XetHub:
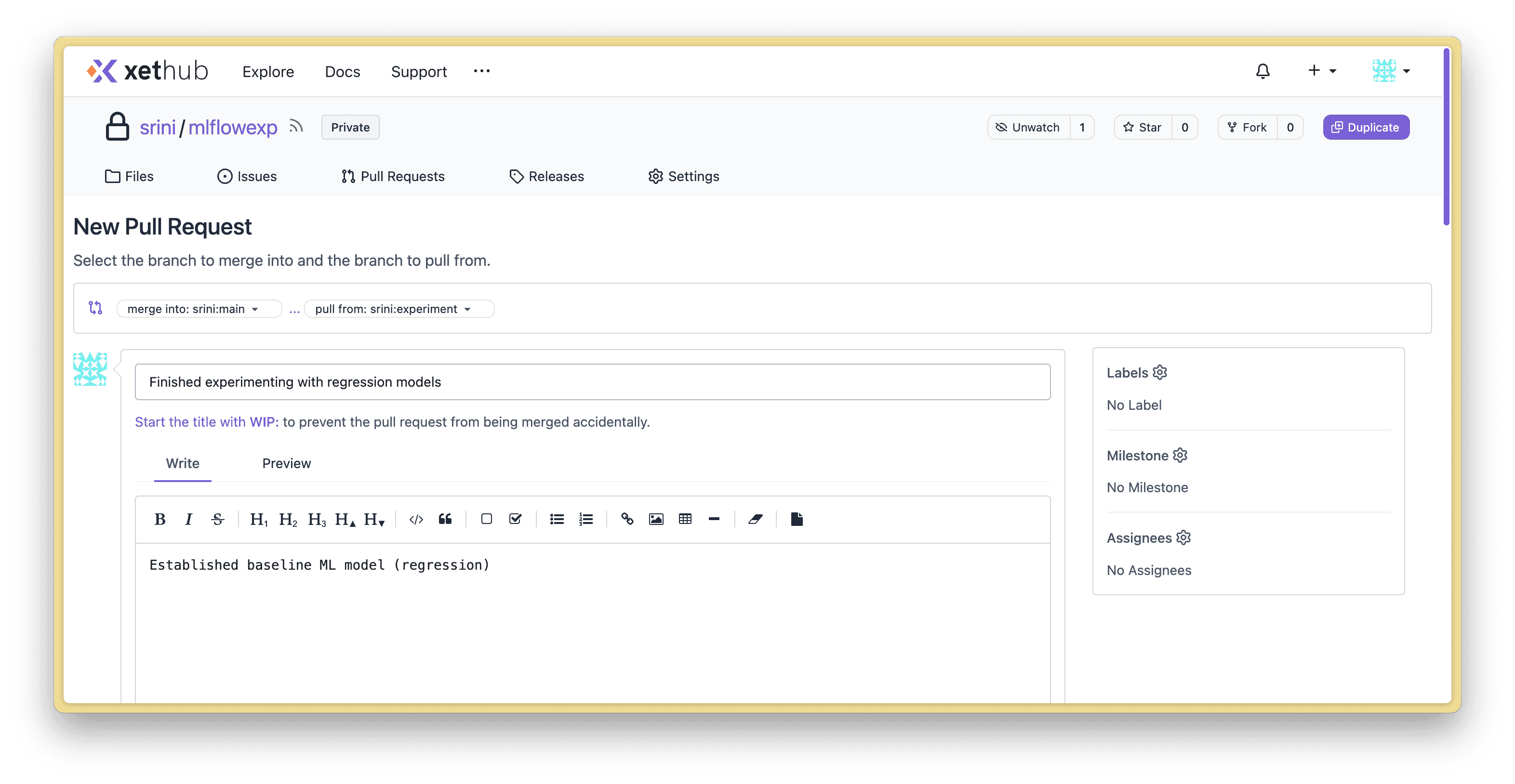
Create pull requests to document & to request merging
GitHub pioneered pull requests for code and we’re extending them for all assets. Use pull requests to add context into the work you’ve done and request merging into main.
Time travel between commits
Using the xet command line interface, you can view the state of a file at a specific point in time:
Or for your entire repo:
Compare models and metrics between branches
Because you can reference files in XetHub repos from arbitrary commits and branches, you can analyze the full universe of metrics, models, etc using custom code.
In the following code snippet, I compare the mean absolute error values for 2 different models in different separate branches for custom comparison.
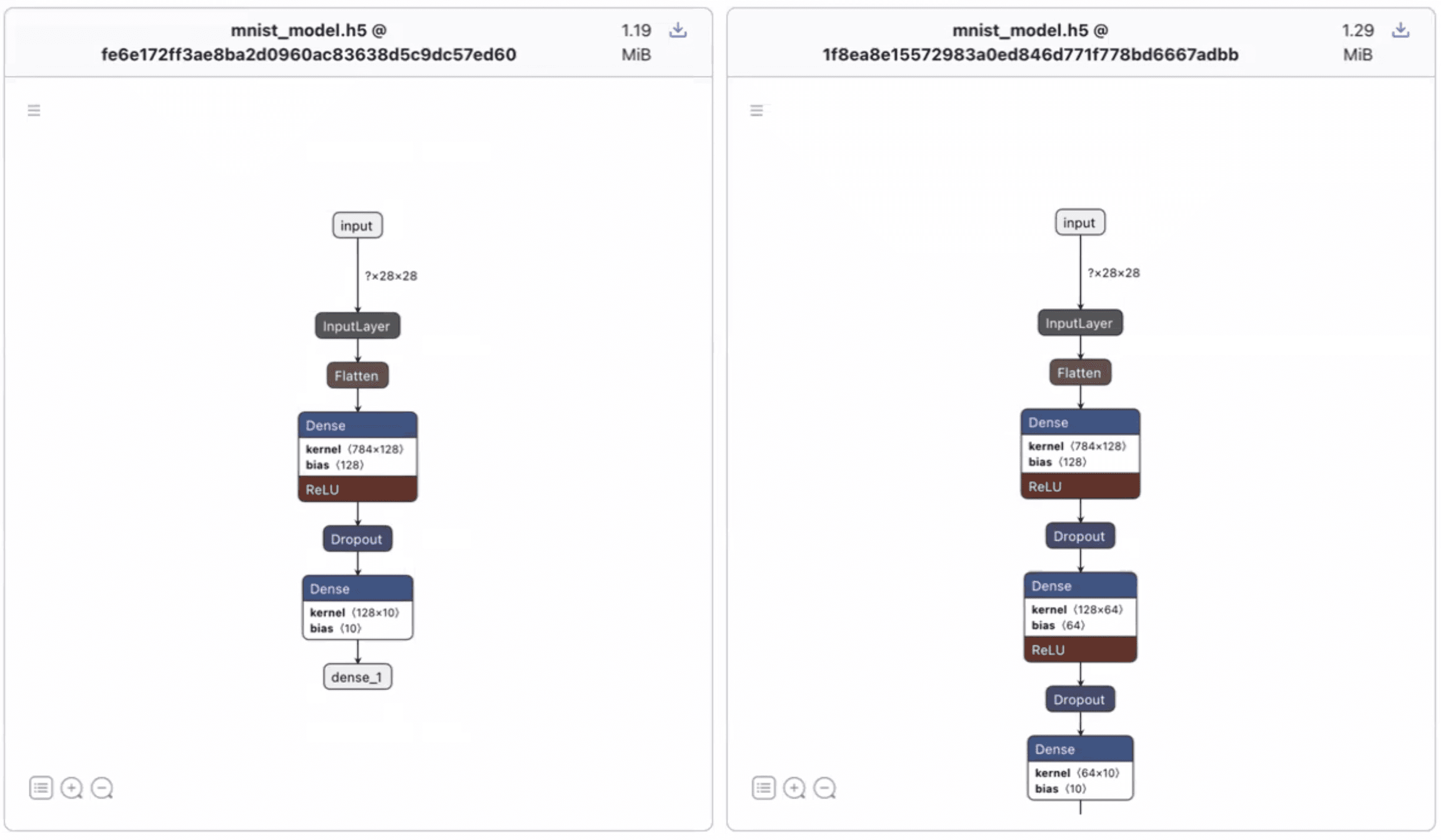
Gain context on your models
Very soon, you’ll be able to view model architectures in commit diffs and while opening model files in XetHub repos (powered by Netron). This feature is just a few weeks from release.
Import MLflow Artifacts from S3
If you already are storing MLflow artifacts in S3, you can use the xet command line to move artifact files into a XetHub repo. This requires that you have the awscli already installed and the minimum AWS policy of AmazonS3ReadOnlyAccess.
Find up-to-date documentation here.
Next Steps
We hope you give our workflow a spin! If you have questions or run into issues, you can engage with the XetHub team in our Slack community or over email.
Share on





